Mainly used for ETL (Extract Transform Load) implementation. Consider an Example of loading data from a flat file to DB.
Start SQL Server Data Tools for Visual Studio (Community edition in my case)















Start SQL Server Data Tools for Visual Studio (Community edition in my case)
In this blog we will simply load
data from one csv file to DB. We will use file available from Indian stock
market called Bhavcopy which gives data about stokes for a day. I am using file
available here
Create new project in tool as
File à
New à
Project (Ctrl + Shift +N). Select integration Services Project
Give a name to this project (in
my case TestStockPriceLoad) and
Click OK.

Now we will need to connect to two endpoints one for source (Flat file) and another for target (SQLServer DB). Here we have two favourite task
- Data flow task
- Execute SQL task
Since we want to transfer data from Source to Destination we are selecting Data flow task. Later in this article we will use Execute SQL task to clean data in temporary table before we load data from flat file. So first thing first we create Data Flow Task by dragging it in Package design window from SSIS Toolbox pan.


Now we create Connection Managers
to be used in Data Flow Task. So right click on Connection Managers and select
New Connection Manager.

Select FLATFILE from options and
click Add button.

Give appropriate name for this
connection manager and select File location.

Then click to Columns option, it will show you what data is there in CSV file. Since we do not want to change anything in this case we will simply click Ok

Now before we create connection manager for target we create a table to store values. For this tutorial we want to load only first 4 columns so we create table with following SQL query.
CREATE TABLE [dbo].[TMP_SCRIP_NSE](
[SCRIP_CODE] [varchar](15) NOT NULL,
[SCRIP_NAME] [varchar](50) NOT NULL,
[SCRIP_GROUP] [varchar](3) NOT NULL,
[SCRIP_TYPE] [varchar](3) NOT NULL
)
Now by following similar steps we create Connection Manager for OLEDB and select table created in last step.

Now double click on Data Flow Task and it will take you to Data Flow tab (alternately click on Data Flow Tab directly).
In this tab from SSIS Tool box panel drag "Flat File Source" to Data Flow tab and similarly drag and drop "OLE DB Destination".

It will show error and that we will fix in next step. Double click on Flat File Source and go to Columns and simply close it as we do not want to change anything for now. Once done it will Red error icon will disappear from Source block. Now drag Blue arrow from source and connect it to destination.

Now double click on target and from "Name of the table or the view" drop down select table we created previously.

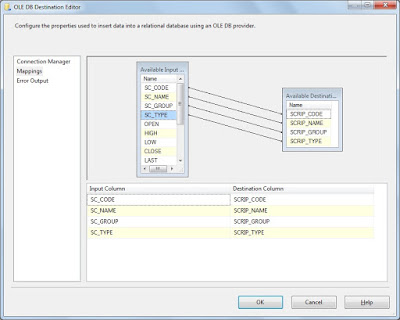
Click on Mappings and map source and target columns as shown.

This will give a warning regarding truncation as source has all default column width. In order to remove this again go to CSV Connection Manager and set width in Advanced tab as follows.

When you try to save these changes it will ask you if you want to update metadata. Select Yes and save the project. Upon Saving the project Warning will go away.
Now run this package either by clicking F5 or by clicking on Start button.
It will build and run the project and show results as shown below.

Alternately you can run SQL query in SQL Server Management Studio and verify if data is loaded correctly or not.







